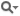| #define APR_BRIGADE_CHECK_CONSISTENCY | ( | b | ) |
checks the ring pointers in a bucket brigade for consistency. an abort() will be triggered if any inconsistencies are found. note: this is a no-op unless APR_BUCKET_DEBUG is defined.
| b | The brigade |
| #define APR_BRIGADE_CONCAT | ( | a, | |||
| b | ) |
do { \ APR_RING_CONCAT(&(a)->list, &(b)->list, apr_bucket, link); \ APR_BRIGADE_CHECK_CONSISTENCY((a)); \ } while (0)
Concatenate brigade b onto the end of brigade a, leaving brigade b empty
| a | The first brigade | |
| b | The second brigade |
| #define APR_BRIGADE_EMPTY | ( | b | ) | APR_RING_EMPTY(&(b)->list, apr_bucket, link) |
Determine if the bucket brigade is empty
| b | The brigade to check |
| #define APR_BRIGADE_FIRST | ( | b | ) | APR_RING_FIRST(&(b)->list) |
Return the first bucket in a brigade
| b | The brigade to query |
| #define APR_BRIGADE_INSERT_HEAD | ( | b, | |||
| e | ) |
do { \ apr_bucket *ap__b = (e); \ APR_RING_INSERT_HEAD(&(b)->list, ap__b, apr_bucket, link); \ APR_BRIGADE_CHECK_CONSISTENCY((b)); \ } while (0)
Insert a single bucket at the front of a brigade
| b | The brigade to add to | |
| e | The bucket to insert |
| #define APR_BRIGADE_INSERT_TAIL | ( | b, | |||
| e | ) |
do { \ apr_bucket *ap__b = (e); \ APR_RING_INSERT_TAIL(&(b)->list, ap__b, apr_bucket, link); \ APR_BRIGADE_CHECK_CONSISTENCY((b)); \ } while (0)
Insert a single bucket at the end of a brigade
| b | The brigade to add to | |
| e | The bucket to insert |
| #define APR_BRIGADE_LAST | ( | b | ) | APR_RING_LAST(&(b)->list) |
Return the last bucket in a brigade
| b | The brigade to query |
| #define APR_BRIGADE_PREPEND | ( | a, | |||
| b | ) |
do { \ APR_RING_PREPEND(&(a)->list, &(b)->list, apr_bucket, link); \ APR_BRIGADE_CHECK_CONSISTENCY((a)); \ } while (0)
Prepend brigade b onto the beginning of brigade a, leaving brigade b empty
| a | The first brigade | |
| b | The second brigade |
| #define APR_BRIGADE_SENTINEL | ( | b | ) | APR_RING_SENTINEL(&(b)->list, apr_bucket, link) |
Wrappers around the RING macros to reduce the verbosity of the code that handles bucket brigades. The magic pointer value that indicates the head of the brigade
while (e != APR_BRIGADE_SENTINEL(b)) {
...
e = APR_BUCKET_NEXT(e);
}
| b | The brigade |
| #define APR_BUCKET_ALLOC_SIZE APR_ALIGN_DEFAULT(2*sizeof(apr_bucket_structs)) |
The amount that apr_bucket_alloc() should allocate in the common case. Note: this is twice as big as apr_bucket_structs to allow breathing room for third-party bucket types.
| #define APR_BUCKET_BUFF_SIZE 8000 |
default bucket buffer size - 8KB minus room for memory allocator headers
| #define APR_BUCKET_CHECK_CONSISTENCY | ( | e | ) |
checks the brigade a bucket is in for ring consistency. an abort() will be triggered if any inconsistencies are found. note: this is a no-op unless APR_BUCKET_DEBUG is defined.
| e | The bucket |
| #define apr_bucket_copy | ( | e, | |||
| c | ) | (e)->type->copy(e, c) |
Copy a bucket.
| e | The bucket to copy | |
| c | Returns a pointer to the new bucket |
| #define apr_bucket_delete | ( | e | ) |
do { \ APR_BUCKET_REMOVE(e); \ apr_bucket_destroy(e); \ } while (0)
Delete a bucket by removing it from its brigade (if any) and then destroying it.
APR_BUCKET_REMOVE(e);
apr_bucket_destroy(e);
| e | The bucket to delete |
| #define apr_bucket_destroy | ( | e | ) |
do { \ (e)->type->destroy((e)->data); \ (e)->free(e); \ } while (0)
Free the resources used by a bucket. If multiple buckets refer to the same resource it is freed when the last one goes away.
| e | The bucket to destroy |
| #define APR_BUCKET_INIT | ( | e | ) | APR_RING_ELEM_INIT((e), link) |
Initialize a new bucket's prev/next pointers
| e | The bucket to initialize |
| #define APR_BUCKET_INSERT_AFTER | ( | a, | |||
| b | ) |
do { \ apr_bucket *ap__a = (a), *ap__b = (b); \ APR_RING_INSERT_AFTER(ap__a, ap__b, link); \ APR_BUCKET_CHECK_CONSISTENCY(ap__a); \ } while (0)
Insert a single bucket after a specified bucket
| a | The bucket to insert after | |
| b | The bucket to insert |
| #define APR_BUCKET_INSERT_BEFORE | ( | a, | |||
| b | ) |
do { \ apr_bucket *ap__a = (a), *ap__b = (b); \ APR_RING_INSERT_BEFORE(ap__a, ap__b, link); \ APR_BUCKET_CHECK_CONSISTENCY(ap__a); \ } while (0)
Insert a single bucket before a specified bucket
| a | The bucket to insert before | |
| b | The bucket to insert |
| #define APR_BUCKET_IS_EOS | ( | e | ) | ((e)->type == &apr_bucket_type_eos) |
Determine if a bucket is an EOS bucket
| e | The bucket to inspect |
| #define APR_BUCKET_IS_FILE | ( | e | ) | ((e)->type == &apr_bucket_type_file) |
Determine if a bucket is a FILE bucket
| e | The bucket to inspect |
| #define APR_BUCKET_IS_FLUSH | ( | e | ) | ((e)->type == &apr_bucket_type_flush) |
Determine if a bucket is a FLUSH bucket
| e | The bucket to inspect |
| #define APR_BUCKET_IS_HEAP | ( | e | ) | ((e)->type == &apr_bucket_type_heap) |
Determine if a bucket is a HEAP bucket
| e | The bucket to inspect |
| #define APR_BUCKET_IS_IMMORTAL | ( | e | ) | ((e)->type == &apr_bucket_type_immortal) |
Determine if a bucket is a IMMORTAL bucket
| e | The bucket to inspect |
| #define APR_BUCKET_IS_METADATA | ( | e | ) | ((e)->type->is_metadata) |
Determine if a bucket contains metadata. An empty bucket is safe to arbitrarily remove if and only if this is false.
| e | The bucket to inspect |
| #define APR_BUCKET_IS_MMAP | ( | e | ) | ((e)->type == &apr_bucket_type_mmap) |
Determine if a bucket is a MMAP bucket
| e | The bucket to inspect |
| #define APR_BUCKET_IS_PIPE | ( | e | ) | ((e)->type == &apr_bucket_type_pipe) |
Determine if a bucket is a PIPE bucket
| e | The bucket to inspect |
| #define APR_BUCKET_IS_POOL | ( | e | ) | ((e)->type == &apr_bucket_type_pool) |
Determine if a bucket is a POOL bucket
| e | The bucket to inspect |
| #define APR_BUCKET_IS_SOCKET | ( | e | ) | ((e)->type == &apr_bucket_type_socket) |
Determine if a bucket is a SOCKET bucket
| e | The bucket to inspect |
| #define APR_BUCKET_IS_TRANSIENT | ( | e | ) | ((e)->type == &apr_bucket_type_transient) |
Determine if a bucket is a TRANSIENT bucket
| e | The bucket to inspect |
| #define APR_BUCKET_NEXT | ( | e | ) | APR_RING_NEXT((e), link) |
Get the next bucket in the list
| e | The current bucket |
| #define APR_BUCKET_PREV | ( | e | ) | APR_RING_PREV((e), link) |
Get the previous bucket in the list
| e | The current bucket |
| #define apr_bucket_read | ( | e, | |||
| str, | |||||
| len, | |||||
| block | ) | (e)->type->read(e, str, len, block) |
Read some data from the bucket.
The apr_bucket_read function returns a convenient amount of data from the bucket provided, writing the address and length of the data to the pointers provided by the caller. The function tries as hard as possible to avoid a memory copy.
Buckets are expected to be a member of a brigade at the time they are read.
In typical application code, buckets are read in a loop, and after each bucket is read and processed, it is moved or deleted from the brigade and the next bucket read.
The definition of "convenient" depends on the type of bucket that is being read, and is decided by APR. In the case of memory based buckets such as heap and immortal buckets, a pointer will be returned to the location of the buffer containing the complete contents of the bucket.
Some buckets, such as the socket bucket, might have no concept of length. If an attempt is made to read such a bucket, the apr_bucket_read function will read a convenient amount of data from the socket. The socket bucket is magically morphed into a heap bucket containing the just-read data, and a new socket bucket is inserted just after this heap bucket.
To understand why apr_bucket_read might do this, consider the loop described above to read and process buckets. The current bucket is magically morphed into a heap bucket and returned to the caller. The caller processes the data, and deletes the heap bucket, moving onto the next bucket, the new socket bucket. This process repeats, giving the illusion of a bucket brigade that contains potentially infinite amounts of data. It is up to the caller to decide at what point to stop reading buckets.
Some buckets, such as the file bucket, might have a fixed size, but be significantly larger than is practical to store in RAM in one go. As with the socket bucket, if an attempt is made to read from a file bucket, the file bucket is magically morphed into a heap bucket containing a convenient amount of data read from the current offset in the file. During the read, the offset will be moved forward on the file, and a new file bucket will be inserted directly after the current bucket representing the remainder of the file. If the heap bucket was large enough to store the whole remainder of the file, no more file buckets are inserted, and the file bucket will disappear completely.
The pattern for reading buckets described above does create the illusion that the code is willing to swallow buckets that might be too large for the system to handle in one go. This however is just an illusion: APR will always ensure that large (file) or infinite (socket) buckets are broken into convenient bite sized heap buckets before data is returned to the caller.
There is a potential gotcha to watch for: if buckets are read in a loop, and aren't deleted after being processed, the potentially large bucket will slowly be converted into RAM resident heap buckets. If the file is larger than available RAM, an out of memory condition could be caused if the application is not careful to manage this.
| e | The bucket to read from | |
| str | The location to store a pointer to the data in | |
| len | The location to store the amount of data read | |
| block | Whether the read function blocks |
| #define APR_BUCKET_REMOVE | ( | e | ) | APR_RING_REMOVE((e), link) |
Remove a bucket from its bucket brigade
| e | The bucket to remove |
| #define apr_bucket_setaside | ( | e, | |||
| p | ) | (e)->type->setaside(e,p) |
Setaside data so that stack data is not destroyed on returning from the function
| e | The bucket to setaside | |
| p | The pool to setaside into |
| #define apr_bucket_split | ( | e, | |||
| point | ) | (e)->type->split(e, point) |
Split one bucket in two at the point provided.
Once split, the original bucket becomes the first of the two new buckets.
(It is assumed that the bucket is a member of a brigade when this function is called).
| e | The bucket to split | |
| point | The offset to split the bucket at |
| typedef apr_status_t(* apr_brigade_flush)(apr_bucket_brigade *bb, void *ctx) |
Function called when a brigade should be flushed
| typedef struct apr_bucket apr_bucket |
| typedef struct apr_bucket_alloc_t apr_bucket_alloc_t |
| typedef struct apr_bucket_brigade apr_bucket_brigade |
The one-sentence buzzword-laden overview: Bucket brigades represent a complex data stream that can be passed through a layered IO system without unnecessary copying. A longer overview follows...
A bucket brigade is a doubly linked list (ring) of buckets, so we aren't limited to inserting at the front and removing at the end. Buckets are only passed around as members of a brigade, although singleton buckets can occur for short periods of time.
Buckets are data stores of various types. They can refer to data in memory, or part of a file or mmap area, or the output of a process, etc. Buckets also have some type-dependent accessor functions: read, split, copy, setaside, and destroy.
read returns the address and size of the data in the bucket. If the data isn't in memory then it is read in and the bucket changes type so that it can refer to the new location of the data. If all the data doesn't fit in the bucket then a new bucket is inserted into the brigade to hold the rest of it.
split divides the data in a bucket into two regions. After a split the original bucket refers to the first part of the data and a new bucket inserted into the brigade after the original bucket refers to the second part of the data. Reference counts are maintained as necessary.
setaside ensures that the data in the bucket has a long enough lifetime. Sometimes it is convenient to create a bucket referring to data on the stack in the expectation that it will be consumed (output to the network) before the stack is unwound. If that expectation turns out not to be valid, the setaside function is called to move the data somewhere safer.
copy makes a duplicate of the bucket structure as long as it's possible to have multiple references to a single copy of the data itself. Not all bucket types can be copied.
destroy maintains the reference counts on the resources used by a bucket and frees them if necessary.
Note: all of the above functions have wrapper macros (apr_bucket_read(), apr_bucket_destroy(), etc), and those macros should be used rather than using the function pointers directly.
To write a bucket brigade, they are first made into an iovec, so that we don't write too little data at one time. Currently we ignore compacting the buckets into as few buckets as possible, but if we really want good performance, then we need to compact the buckets before we convert to an iovec, or possibly while we are converting to an iovec.
| typedef struct apr_bucket_file apr_bucket_file |
| typedef struct apr_bucket_heap apr_bucket_heap |
| typedef struct apr_bucket_mmap apr_bucket_mmap |
| typedef struct apr_bucket_pool apr_bucket_pool |
| typedef struct apr_bucket_refcount apr_bucket_refcount |
| typedef union apr_bucket_structs apr_bucket_structs |
| typedef struct apr_bucket_type_t apr_bucket_type_t |
| enum apr_read_type_e |
| apr_status_t apr_brigade_cleanup | ( | void * | data | ) |
empty out an entire bucket brigade. This includes destroying all of the buckets within the bucket brigade's bucket list. This is similar to apr_brigade_destroy(), except that it does not deregister the brigade's pool cleanup function.
| data | The bucket brigade to clean up |
| apr_bucket_brigade* apr_brigade_create | ( | apr_pool_t * | p, | |
| apr_bucket_alloc_t * | list | |||
| ) |
Create a new bucket brigade. The bucket brigade is originally empty.
| p | The pool to associate with the brigade. Data is not allocated out of the pool, but a cleanup is registered. | |
| list | The bucket allocator to use |
| apr_status_t apr_brigade_destroy | ( | apr_bucket_brigade * | b | ) |
destroy an entire bucket brigade. This includes destroying all of the buckets within the bucket brigade's bucket list.
| b | The bucket brigade to destroy |
| apr_status_t apr_brigade_flatten | ( | apr_bucket_brigade * | bb, | |
| char * | c, | |||
| apr_size_t * | len | |||
| ) |
Take a bucket brigade and store the data in a flat char*
| bb | The bucket brigade to create the char* from | |
| c | The char* to write into | |
| len | The maximum length of the char array. On return, it is the actual length of the char array. |
| apr_bucket* apr_brigade_insert_file | ( | apr_bucket_brigade * | bb, | |
| apr_file_t * | f, | |||
| apr_off_t | start, | |||
| apr_off_t | len, | |||
| apr_pool_t * | p | |||
| ) |
Utility function to insert a file (or a segment of a file) onto the end of the brigade. The file is split into multiple buckets if it is larger than the maximum size which can be represented by a single bucket.
| bb | the brigade to insert into | |
| f | the file to insert | |
| start | the offset of the start of the segment | |
| len | the length of the segment of the file to insert | |
| p | pool from which file buckets are allocated |
| apr_status_t apr_brigade_length | ( | apr_bucket_brigade * | bb, | |
| int | read_all, | |||
| apr_off_t * | length | |||
| ) |
Return the total length of the brigade.
| bb | The brigade to compute the length of | |
| read_all | Read unknown-length buckets to force a size | |
| length | Returns the length of the brigade (up to the end, or up to a bucket read error), or -1 if the brigade has buckets of indeterminate length and read_all is 0. |
| apr_status_t apr_brigade_partition | ( | apr_bucket_brigade * | b, | |
| apr_off_t | point, | |||
| apr_bucket ** | after_point | |||
| ) |
Partition a bucket brigade at a given offset (in bytes from the start of the brigade). This is useful whenever a filter wants to use known ranges of bytes from the brigade; the ranges can even overlap.
| b | The brigade to partition | |
| point | The offset at which to partition the brigade | |
| after_point | Returns a pointer to the first bucket after the partition |
| apr_status_t apr_brigade_pflatten | ( | apr_bucket_brigade * | bb, | |
| char ** | c, | |||
| apr_size_t * | len, | |||
| apr_pool_t * | pool | |||
| ) |
Creates a pool-allocated string representing a flat bucket brigade
| bb | The bucket brigade to create the char array from | |
| c | On return, the allocated char array | |
| len | On return, the length of the char array. | |
| pool | The pool to allocate the string from. |
| apr_status_t apr_brigade_printf | ( | apr_bucket_brigade * | b, | |
| apr_brigade_flush | flush, | |||
| void * | ctx, | |||
| const char * | fmt, | |||
| ... | ||||
| ) |
Evaluate a printf and put the resulting string at the end of the bucket brigade.
| b | The brigade to write to | |
| flush | The flush function to use if the brigade is full | |
| ctx | The structure to pass to the flush function | |
| fmt | The format of the string to write | |
| ... | The arguments to fill out the format |
| apr_status_t apr_brigade_putc | ( | apr_bucket_brigade * | b, | |
| apr_brigade_flush | flush, | |||
| void * | ctx, | |||
| const char | c | |||
| ) |
This function writes a character into a bucket brigade.
| b | The bucket brigade to add to | |
| flush | The flush function to use if the brigade is full | |
| ctx | The structure to pass to the flush function | |
| c | The character to add |
| apr_status_t apr_brigade_puts | ( | apr_bucket_brigade * | bb, | |
| apr_brigade_flush | flush, | |||
| void * | ctx, | |||
| const char * | str | |||
| ) |
This function writes a string into a bucket brigade.
| bb | The bucket brigade to add to | |
| flush | The flush function to use if the brigade is full | |
| ctx | The structure to pass to the flush function | |
| str | The string to add |
| apr_status_t apr_brigade_putstrs | ( | apr_bucket_brigade * | b, | |
| apr_brigade_flush | flush, | |||
| void * | ctx, | |||
| ... | ||||
| ) |
This function writes an unspecified number of strings into a bucket brigade.
| b | The bucket brigade to add to | |
| flush | The flush function to use if the brigade is full | |
| ctx | The structure to pass to the flush function | |
| ... | The strings to add |
| apr_bucket_brigade* apr_brigade_split | ( | apr_bucket_brigade * | b, | |
| apr_bucket * | e | |||
| ) |
Create a new bucket brigade and move the buckets from the tail end of an existing brigade into the new brigade. Buckets from e to the last bucket (inclusively) of brigade b are moved from b to the returned brigade.
| b | The brigade to split | |
| e | The first bucket to move |
| apr_bucket_brigade* apr_brigade_split_ex | ( | apr_bucket_brigade * | b, | |
| apr_bucket * | e, | |||
| apr_bucket_brigade * | a | |||
| ) |
Move the buckets from the tail end of the existing brigade b into the brigade a. If a is NULL a new brigade is created. Buckets from e to the last bucket (inclusively) of brigade b are moved from b to the returned brigade a.
| b | The brigade to split | |
| e | The first bucket to move | |
| a | The brigade which should be used for the result or NULL if a new brigade should be created. The brigade a will be cleared if it is not empty. |
| apr_status_t apr_brigade_split_line | ( | apr_bucket_brigade * | bbOut, | |
| apr_bucket_brigade * | bbIn, | |||
| apr_read_type_e | block, | |||
| apr_off_t | maxbytes | |||
| ) |
Split a brigade to represent one LF line.
| bbOut | The bucket brigade that will have the LF line appended to. | |
| bbIn | The input bucket brigade to search for a LF-line. | |
| block | The blocking mode to be used to split the line. | |
| maxbytes | The maximum bytes to read. If this many bytes are seen without a LF, the brigade will contain a partial line. |
| apr_status_t apr_brigade_to_iovec | ( | apr_bucket_brigade * | b, | |
| struct iovec * | vec, | |||
| int * | nvec | |||
| ) |
Create an iovec of the elements in a bucket_brigade... return number of elements used. This is useful for writing to a file or to the network efficiently.
| b | The bucket brigade to create the iovec from | |
| vec | The iovec to create | |
| nvec | The number of elements in the iovec. On return, it is the number of iovec elements actually filled out. |
| apr_status_t apr_brigade_vprintf | ( | apr_bucket_brigade * | b, | |
| apr_brigade_flush | flush, | |||
| void * | ctx, | |||
| const char * | fmt, | |||
| va_list | va | |||
| ) |
Evaluate a printf and put the resulting string at the end of the bucket brigade.
| b | The brigade to write to | |
| flush | The flush function to use if the brigade is full | |
| ctx | The structure to pass to the flush function | |
| fmt | The format of the string to write | |
| va | The arguments to fill out the format |
| apr_status_t apr_brigade_vputstrs | ( | apr_bucket_brigade * | b, | |
| apr_brigade_flush | flush, | |||
| void * | ctx, | |||
| va_list | va | |||
| ) |
This function writes a list of strings into a bucket brigade.
| b | The bucket brigade to add to | |
| flush | The flush function to use if the brigade is full | |
| ctx | The structure to pass to the flush function | |
| va | A list of strings to add |
| apr_status_t apr_brigade_write | ( | apr_bucket_brigade * | b, | |
| apr_brigade_flush | flush, | |||
| void * | ctx, | |||
| const char * | str, | |||
| apr_size_t | nbyte | |||
| ) |
This function writes a string into a bucket brigade.
The apr_brigade_write function attempts to be efficient with the handling of heap buckets. Regardless of the amount of data stored inside a heap bucket, heap buckets are a fixed size to promote their reuse.
If an attempt is made to write a string to a brigade that already ends with a heap bucket, this function will attempt to pack the string into the remaining space in the previous heap bucket, before allocating a new heap bucket.
This function always returns APR_SUCCESS, unless a flush function is passed, in which case the return value of the flush function will be returned if used.
| b | The bucket brigade to add to | |
| flush | The flush function to use if the brigade is full | |
| ctx | The structure to pass to the flush function | |
| str | The string to add | |
| nbyte | The number of bytes to write |
| apr_status_t apr_brigade_writev | ( | apr_bucket_brigade * | b, | |
| apr_brigade_flush | flush, | |||
| void * | ctx, | |||
| const struct iovec * | vec, | |||
| apr_size_t | nvec | |||
| ) |
This function writes multiple strings into a bucket brigade.
| b | The bucket brigade to add to | |
| flush | The flush function to use if the brigade is full | |
| ctx | The structure to pass to the flush function | |
| vec | The strings to add (address plus length for each) | |
| nvec | The number of entries in iovec |
| void* apr_bucket_alloc | ( | apr_size_t | size, | |
| apr_bucket_alloc_t * | list | |||
| ) |
Allocate memory for use by the buckets.
| size | The amount to allocate. | |
| list | The allocator from which to allocate the memory. |
| apr_bucket_alloc_t* apr_bucket_alloc_create | ( | apr_pool_t * | p | ) |
Create a bucket allocator.
| p | This pool's underlying apr_allocator_t is used to allocate memory for the bucket allocator. When the pool is destroyed, the bucket allocator's cleanup routine will free all memory that has been allocated from it. |
| apr_bucket_alloc_t* apr_bucket_alloc_create_ex | ( | apr_allocator_t * | allocator | ) |
Create a bucket allocator.
| allocator | This apr_allocator_t is used to allocate both the bucket allocator and all memory handed out by the bucket allocator. The caller is responsible for destroying the bucket allocator and the apr_allocator_t -- no automatic cleanups will happen. |
| void apr_bucket_alloc_destroy | ( | apr_bucket_alloc_t * | list | ) |
Destroy a bucket allocator.
| list | The allocator to be destroyed |
| apr_status_t apr_bucket_copy_notimpl | ( | apr_bucket * | e, | |
| apr_bucket ** | c | |||
| ) |
A place holder function that signifies that the copy function was not implemented for this bucket
| e | The bucket to copy | |
| c | Returns a pointer to the new bucket |
| void apr_bucket_destroy_noop | ( | void * | data | ) |
A place holder function that signifies that this bucket does not need to do anything special to be destroyed. That's only the case for buckets that either have no data (metadata buckets) or buckets whose data pointer points to something that's not a bucket-type-specific structure, as with simple buckets where data points to a string and pipe buckets where data points directly to the apr_file_t.
| data | The bucket data to destroy |
| apr_bucket* apr_bucket_eos_create | ( | apr_bucket_alloc_t * | list | ) |
Create an End of Stream bucket. This indicates that there is no more data coming from down the filter stack. All filters should flush at this point.
| list | The freelist from which this bucket should be allocated |
| apr_bucket* apr_bucket_eos_make | ( | apr_bucket * | b | ) |
Make the bucket passed in an EOS bucket. This indicates that there is no more data coming from down the filter stack. All filters should flush at this point.
| b | The bucket to make into an EOS bucket |
| apr_bucket* apr_bucket_file_create | ( | apr_file_t * | fd, | |
| apr_off_t | offset, | |||
| apr_size_t | len, | |||
| apr_pool_t * | p, | |||
| apr_bucket_alloc_t * | list | |||
| ) |
Create a bucket referring to a file.
| fd | The file to put in the bucket | |
| offset | The offset where the data of interest begins in the file | |
| len | The amount of data in the file we are interested in | |
| p | The pool into which any needed structures should be created while reading from this file bucket | |
| list | The freelist from which this bucket should be allocated |
| apr_status_t apr_bucket_file_enable_mmap | ( | apr_bucket * | b, | |
| int | enabled | |||
| ) |
Enable or disable memory-mapping for a FILE bucket (default is enabled)
| b | The bucket | |
| enabled | Whether memory-mapping should be enabled |
| apr_bucket* apr_bucket_file_make | ( | apr_bucket * | b, | |
| apr_file_t * | fd, | |||
| apr_off_t | offset, | |||
| apr_size_t | len, | |||
| apr_pool_t * | p | |||
| ) |
Make the bucket passed in a bucket refer to a file
| b | The bucket to make into a FILE bucket | |
| fd | The file to put in the bucket | |
| offset | The offset where the data of interest begins in the file | |
| len | The amount of data in the file we are interested in | |
| p | The pool into which any needed structures should be created while reading from this file bucket |
| apr_bucket* apr_bucket_flush_create | ( | apr_bucket_alloc_t * | list | ) |
Create a flush bucket. This indicates that filters should flush their data. There is no guarantee that they will flush it, but this is the best we can do.
| list | The freelist from which this bucket should be allocated |
| apr_bucket* apr_bucket_flush_make | ( | apr_bucket * | b | ) |
Make the bucket passed in a FLUSH bucket. This indicates that filters should flush their data. There is no guarantee that they will flush it, but this is the best we can do.
| b | The bucket to make into a FLUSH bucket |
| void apr_bucket_free | ( | void * | block | ) |
Free memory previously allocated with apr_bucket_alloc().
| block | The block of memory to be freed. |
| apr_bucket* apr_bucket_heap_create | ( | const char * | buf, | |
| apr_size_t | nbyte, | |||
| void(*)(void *data) | free_func, | |||
| apr_bucket_alloc_t * | list | |||
| ) |
Create a bucket referring to memory on the heap. If the caller asks for the data to be copied, this function always allocates 4K of memory so that more data can be added to the bucket without requiring another allocation. Therefore not all the data may be put into the bucket. If copying is not requested then the bucket takes over responsibility for free()ing the memory.
| buf | The buffer to insert into the bucket | |
| nbyte | The size of the buffer to insert. | |
| free_func | Function to use to free the data; NULL indicates that the bucket should make a copy of the data | |
| list | The freelist from which this bucket should be allocated |
| apr_bucket* apr_bucket_heap_make | ( | apr_bucket * | b, | |
| const char * | buf, | |||
| apr_size_t | nbyte, | |||
| void(*)(void *data) | free_func | |||
| ) |
Make the bucket passed in a bucket refer to heap data
| b | The bucket to make into a HEAP bucket | |
| buf | The buffer to insert into the bucket | |
| nbyte | The size of the buffer to insert. | |
| free_func | Function to use to free the data; NULL indicates that the bucket should make a copy of the data |
| apr_bucket* apr_bucket_immortal_create | ( | const char * | buf, | |
| apr_size_t | nbyte, | |||
| apr_bucket_alloc_t * | list | |||
| ) |
Create a bucket referring to long-lived data.
| buf | The data to insert into the bucket | |
| nbyte | The size of the data to insert. | |
| list | The freelist from which this bucket should be allocated |
| apr_bucket* apr_bucket_immortal_make | ( | apr_bucket * | b, | |
| const char * | buf, | |||
| apr_size_t | nbyte | |||
| ) |
Make the bucket passed in a bucket refer to long-lived data
| b | The bucket to make into a IMMORTAL bucket | |
| buf | The data to insert into the bucket | |
| nbyte | The size of the data to insert. |
| apr_bucket* apr_bucket_mmap_create | ( | apr_mmap_t * | mm, | |
| apr_off_t | start, | |||
| apr_size_t | length, | |||
| apr_bucket_alloc_t * | list | |||
| ) |
Create a bucket referring to mmap()ed memory.
| mm | The mmap to insert into the bucket | |
| start | The offset of the first byte in the mmap that this bucket refers to | |
| length | The number of bytes referred to by this bucket | |
| list | The freelist from which this bucket should be allocated |
| apr_bucket* apr_bucket_mmap_make | ( | apr_bucket * | b, | |
| apr_mmap_t * | mm, | |||
| apr_off_t | start, | |||
| apr_size_t | length | |||
| ) |
Make the bucket passed in a bucket refer to an MMAP'ed file
| b | The bucket to make into a MMAP bucket | |
| mm | The mmap to insert into the bucket | |
| start | The offset of the first byte in the mmap that this bucket refers to | |
| length | The number of bytes referred to by this bucket |
| apr_bucket* apr_bucket_pipe_create | ( | apr_file_t * | thispipe, | |
| apr_bucket_alloc_t * | list | |||
| ) |
Create a bucket referring to a pipe.
| thispipe | The pipe to put in the bucket | |
| list | The freelist from which this bucket should be allocated |
| apr_bucket* apr_bucket_pipe_make | ( | apr_bucket * | b, | |
| apr_file_t * | thispipe | |||
| ) |
Make the bucket passed in a bucket refer to a pipe
| b | The bucket to make into a PIPE bucket | |
| thispipe | The pipe to put in the bucket |
| apr_bucket* apr_bucket_pool_create | ( | const char * | buf, | |
| apr_size_t | length, | |||
| apr_pool_t * | pool, | |||
| apr_bucket_alloc_t * | list | |||
| ) |
Create a bucket referring to memory allocated from a pool.
| buf | The buffer to insert into the bucket | |
| length | The number of bytes referred to by this bucket | |
| pool | The pool the memory was allocated from | |
| list | The freelist from which this bucket should be allocated |
| apr_bucket* apr_bucket_pool_make | ( | apr_bucket * | b, | |
| const char * | buf, | |||
| apr_size_t | length, | |||
| apr_pool_t * | pool | |||
| ) |
Make the bucket passed in a bucket refer to pool data
| b | The bucket to make into a pool bucket | |
| buf | The buffer to insert into the bucket | |
| length | The number of bytes referred to by this bucket | |
| pool | The pool the memory was allocated from |
| apr_status_t apr_bucket_setaside_noop | ( | apr_bucket * | data, | |
| apr_pool_t * | pool | |||
| ) |
This function simply returns APR_SUCCESS to denote that the bucket does not require anything to happen for its setaside() function. This is appropriate for buckets that have "immortal" data -- the data will live at least as long as the bucket.
| data | The bucket to setaside | |
| pool | The pool defining the desired lifetime of the bucket data |
| apr_status_t apr_bucket_setaside_notimpl | ( | apr_bucket * | data, | |
| apr_pool_t * | pool | |||
| ) |
A place holder function that signifies that the setaside function was not implemented for this bucket
| data | The bucket to setaside | |
| pool | The pool defining the desired lifetime of the bucket data |
| apr_status_t apr_bucket_shared_copy | ( | apr_bucket * | a, | |
| apr_bucket ** | b | |||
| ) |
Copy a refcounted bucket, incrementing the reference count. Most reference-counting bucket types will be able to use this function as their copy function without any additional type-specific handling.
| a | The bucket to copy | |
| b | Returns a pointer to the new bucket |
| int apr_bucket_shared_destroy | ( | void * | data | ) |
Decrement the refcount of the data in the bucket. This function should only be called by type-specific bucket destruction functions.
| data | The private data pointer from the bucket to be destroyed |
| apr_bucket* apr_bucket_shared_make | ( | apr_bucket * | b, | |
| void * | data, | |||
| apr_off_t | start, | |||
| apr_size_t | length | |||
| ) |
Initialize a bucket containing reference-counted data that may be shared. The caller must allocate the bucket if necessary and initialize its type-dependent fields, and allocate and initialize its own private data structure. This function should only be called by type-specific bucket creation functions.
| b | The bucket to initialize | |
| data | A pointer to the private data structure with the reference count at the start | |
| start | The start of the data in the bucket relative to the private base pointer | |
| length | The length of the data in the bucket |
| apr_status_t apr_bucket_shared_split | ( | apr_bucket * | b, | |
| apr_size_t | point | |||
| ) |
Split a bucket into two at the given point, and adjust the refcount to the underlying data. Most reference-counting bucket types will be able to use this function as their split function without any additional type-specific handling.
| b | The bucket to be split | |
| point | The offset of the first byte in the new bucket |
| apr_status_t apr_bucket_simple_copy | ( | apr_bucket * | a, | |
| apr_bucket ** | b | |||
| ) |
Copy a simple bucket. Most non-reference-counting buckets that allow multiple references to the same block of data (eg transient and immortal) will use this as their copy function without any additional type-specific handling.
| a | The bucket to copy | |
| b | Returns a pointer to the new bucket |
| apr_status_t apr_bucket_simple_split | ( | apr_bucket * | b, | |
| apr_size_t | point | |||
| ) |
Split a simple bucket into two at the given point. Most non-reference counting buckets that allow multiple references to the same block of data (eg transient and immortal) will use this as their split function without any additional type-specific handling.
| b | The bucket to be split | |
| point | The offset of the first byte in the new bucket |
| apr_bucket* apr_bucket_socket_create | ( | apr_socket_t * | thissock, | |
| apr_bucket_alloc_t * | list | |||
| ) |
Create a bucket referring to a socket.
| thissock | The socket to put in the bucket | |
| list | The freelist from which this bucket should be allocated |
| apr_bucket* apr_bucket_socket_make | ( | apr_bucket * | b, | |
| apr_socket_t * | thissock | |||
| ) |
Make the bucket passed in a bucket refer to a socket
| b | The bucket to make into a SOCKET bucket | |
| thissock | The socket to put in the bucket |
| apr_status_t apr_bucket_split_notimpl | ( | apr_bucket * | data, | |
| apr_size_t | point | |||
| ) |
A place holder function that signifies that the split function was not implemented for this bucket
| data | The bucket to split | |
| point | The location to split the bucket |
| apr_bucket* apr_bucket_transient_create | ( | const char * | buf, | |
| apr_size_t | nbyte, | |||
| apr_bucket_alloc_t * | list | |||
| ) |
Create a bucket referring to data on the stack.
| buf | The data to insert into the bucket | |
| nbyte | The size of the data to insert. | |
| list | The freelist from which this bucket should be allocated |
| apr_bucket* apr_bucket_transient_make | ( | apr_bucket * | b, | |
| const char * | buf, | |||
| apr_size_t | nbyte | |||
| ) |
Make the bucket passed in a bucket refer to stack data
| b | The bucket to make into a TRANSIENT bucket | |
| buf | The data to insert into the bucket | |
| nbyte | The size of the data to insert. |
The EOS bucket type. This signifies that there will be no more data, ever. All filters MUST send all data to the next filter when they receive a bucket of this type
The FILE bucket type. This bucket represents a file on disk
There is no apr_bucket_destroy_notimpl, because destruction is required to be implemented (it could be a noop, but only if that makes sense for the bucket type) The flush bucket type. This signifies that all data should be flushed to the next filter. The flush bucket should be sent with the other buckets.
The HEAP bucket type. This bucket represents a data allocated from the heap.
The IMMORTAL bucket type. This bucket represents a segment of data that the creator is willing to take responsibility for. The core will do nothing with the data in an immortal bucket
The MMAP bucket type. This bucket represents an MMAP'ed file
The PIPE bucket type. This bucket represents a pipe to another program.
The POOL bucket type. This bucket represents a data that was allocated from a pool. IF this bucket is still available when the pool is cleared, the data is copied on to the heap.
The SOCKET bucket type. This bucket represents a socket to another machine
The TRANSIENT bucket type. This bucket represents a data allocated off the stack. When the setaside function is called, this data is copied on to the heap
 1.6.1
1.6.1